(2022-May-08) If you happened to read the Part 1 of this blog series, the main message of it was the Azure Data Factory Copy activity was not just a simple task that can incapsulate source and target datasets definitions, but it also contains other additional capabilities: schema and data type mapping, data consistency verification, sessions logs, incremental copy and many more. This turns that “simple” ADF task into a powerful data integration engine that can exist on its own, though it’s still very underrated and not very well explored.
In this 2nd part, let’s discuss different stages that might be helpful during data flows development to connect the source and target datasets with optional or required data transformation to populate your data warehouse. To discuss various data warehouse options it will also be worth reading one of recent Bill Inmon's posts about it: Burying data warehouse – RIP

Photo by Jiawei Cui: https://www.pexels.com/photo/chrome-pipe-lines-2310904/
Stages/Zones/Layers
If you have ever watched a cooking show, sometimes I join my wife in this type of family entertainment:- ), then you may notice that cooking a meal requires a different set of culinary stages: raw ingredients are collected (this stage is usually is not exposed to viewers), then those raw ingredients go through additional transformation by taking their peals off, slicing into smaller pieces and placing them into separate containers (viewers usually see the prearranged, sliced, portioned ingredients at the start), and then all these prepared ingredients emerge into a final stage of cooking a meal by mixing them, adding spices and applying various complicated and not so cooking methods.
In a similar way, there is a valid place for a stage that would host sourcing raw data, then a different physical and virtual location for a slightly transformed, staged and updated sourcing data which then leads to its final representation that can be exposed and curated to business users.
There could be several stages/layers/zones in a data transformation process, in general at least 3 are recommended, however, it’s up to technical and business teams to agree on this. The same goes with how you decide to name them, it’s less about the labels but more about the real purpose of segregating different zones:
Creativity

The most pragmatic both from the configuration and maintenance perspective would be to replace individual and custom feeds/stages definitions with configurable metadata, which then will drive and define all initial, intermediate and final data flow steps by utilizing a generic set of reusable pipelines. The main idea here is to configure feed metadata (config tables in my case) and only develop a small number of data load pipelines.
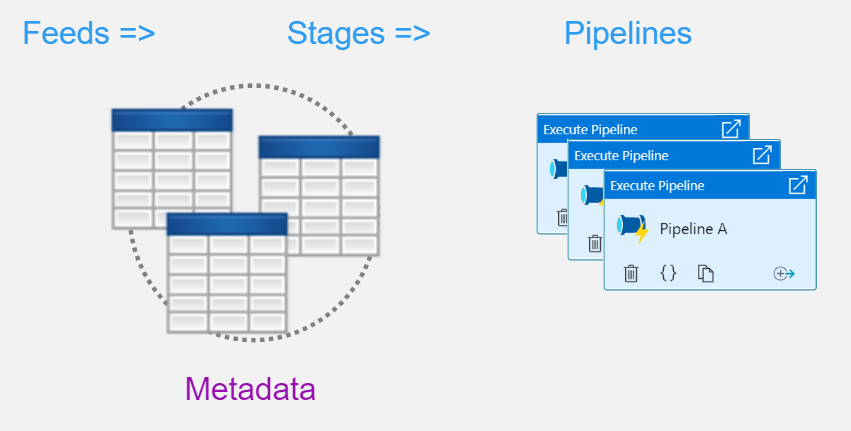
Configuring Metadata
A data model to host sourcing data feeds steps and references to data factory pipelines was a team effort, so I don't hold any copyrights and have no plans to share very detailed code patterns. But this knowledge sharing is rather to have an open discussion to see if any mistakes or pitfalls could be improved.

DataFeed | Data Feed configuration, e.g. sourcing table or file |
DataFeedStages | Data Feed Stages, e.g. raw, staging, edw, etc. |
Schedule | Schedule definition for a particular Data Feed, currently daily or hourly schedules are supported. |
DataFeedExecutionLog | Execution Log for scheduled data feeds |
DataFeedStagesExecutionLog | Execution Log for data feed stages of triggered data feeds |
ColumnMetadata | Column metadata that maps columns between RAW & STG SQL schemas for a table feed |
Metadata samples
DataFeed table

DataFeedStages table

Schedule table

Building less to reuse more
I agree, that building a set of generic ADF pipelines takes more time since you intend to develop something that can adapt to incoming settings of sourcing feeds, just like a T-1000 machine model with its morphing abilities :- )
The first pipeline would scan the table with feed schedule definitions and provide control and orchestration by executing a metadata-driven feed pipeline.

The middle layer or the 2nd pipeline connects all the stages and defines how a supplied metadata-driven feed will be processed. Multiple conditional checks provide additional flexibility for feeds that require more or less than a usual number of stages/layers.

The last and most mysterious pipeline may define what may happen within a relational data store with all the required feed staged data before it turns into a final refined stage of our data warehouse. In this case, the data warehouse is populated with the help of a SQL Server stored procedure, your environment may be different and your use case may alter how your "gold" layer will be populated.
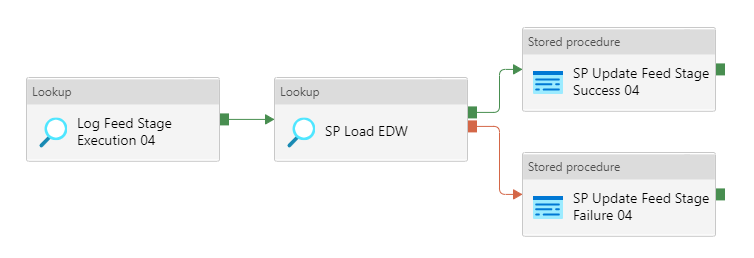
In Part 3 of this blog series, I will talk about dynamic column mapping in the Azure Data Factory pipeline between source and target data connectors, and yes, metadata will play a key role here as well!
Happy data adventures!
Metadata-driven pipelines in Azure Data Factory | Part 1
Metadata-driven pipelines in Azure Data Factory | Part 2
Metadata-driven pipelines in Azure Data Factory | Part 3
Metadata-driven pipelines in Azure Data Factory | Part 4
Comments
Post a Comment