(2022-Mar-04) Looking in the Oxford dictionary, Metadata can be described as "information that describes other information in order to help you understand or use it", as well as Pipeline is "a series of pipes that are usually underground and are used for carrying oil, gas, etc. over long distances"
Yes, I’ve looked at the definition of the pipeline as well, since in my prior work with Azure Data Factory (ADF) this term was rarely used. The other terms, such as data flows, ELT / ELT processes and data integration projects were widely used. Even the SSIS platform had and still has its own term to encapsulate both logical and data transformation flow as a package.
In my personal opinion, the term pipeline is a more elegant way to describe a data flow of user information from a source to destination along with stating additional logical steps to help this data flow to run smoothly and efficiently, just like a water pipeline with no blockage and wasting of resources :- )

Photo by Mohan Reddy from Pexels
A custom approach to building a pipeline in ADF would require efforts to define individual data load connections (source & destination), along with transformation logic (list of attributes/columns and their mapping between source and destination to be explicitly defined, just like during a house construction you would have to plan and build physical pipelines that would distribute incoming water supply to a designated number of “consumers”.
Custom ADF pipeline development is a fun exercise that can help to build your data engineering experience, however, in a long run may not be very sustainable in larger project scope and team projects.
Set of requirements for a data pipeline to succeed:
- Handshake between data source and destination is established
- Data objects (files, tables, etc.) existence is configured and checked
- Mapping between sourcing and destination attributes is configured and validated
- Data flow process starts and completes data transfer from configured sourcing and destination data objects.
While Step 1 and 4 required minimum efforts to establish and monitory, Step 2 & 3 consume large development efforts.
That’s where a metadata-drive approach to build fewer / more generic ADF pipelines that can still support a big variety of data load processes becomes a viable and more recommended solution.
Acknowledging a need for such a simplified process to copy a large number of different data objects, Microsoft back in July of 2021 introduced a template (Metadata-driven data copy task), which was announced General Availability (GA) last week. This provides end-users with a complete solution (set of pipelines) covering Steps 2 & 3 that I have described earlier: to identify data objects for copying and then connect sourcing and destination endpoints. You can read more about this in this documentation article: https://docs.microsoft.com/en-us/azure/data-factory/copy-data-tool-metadata-driven
Since this template solution provides you with the actual pipelines in ADF, you can analyze it in more detail and identify that the most important component here is the actual Data Copy activity task (https://docs.microsoft.com/en-us/azure/data-factory/copy-activity-overview).
It’s a very simple, underrated and yet very powerful tool to transfer datasets between two in and out sides. The whole power of this activity comes from its flexibility to be parameterized and support various data schemas, yes, various, wide and narrow, and yes within the very same data activity task
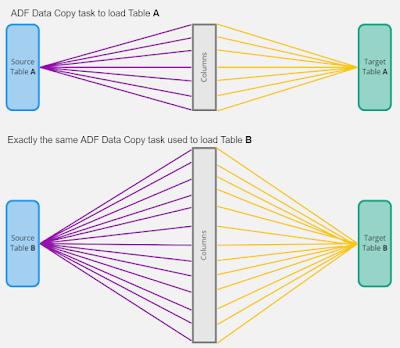
The rest is for your to explore (other parameters and options) as well as monitor this task execution.
In the next blog post, I will describe a possible solution that will allow metadata-driven data factory pipelines for more than one stage (e.g. Landing, Staging, Refined (Reporting) layers).
Metadata-driven pipelines in Azure Data Factory | Part 1
Metadata-driven pipelines in Azure Data Factory | Part 2
Metadata-driven pipelines in Azure Data Factory | Part 3
Metadata-driven pipelines in Azure Data Factory | Part 4
Like it. I always read your blog. Thank you so much for continuing posting it.
ReplyDeleteThank you, Hemant!
Deletewhere can I find Part 2 ?
ReplyDeleteI had other commitments to fulfill, but the part 2 & 3 are coming.
Delete