(2023-Oct-15) When something important disappears, it's natural to start asking questions and looking for answers, especially when that missing piece has had a significant impact on your life.
Similarly, when data that used to exist in your sourcing system suddenly vanishes without any trace, you're likely to react in a similar way. You might find yourself reaching out to higher authorities to understand why the existing data management system design allowed this to happen. Your colleagues might wonder if better ways to handle such data-related issues exist. Ultimately, you'll embark on a quest to question yourself about what could have been done differently to avoid the complete loss of that crucial data.
Paul Felix wrote a good article on “Dealing with Deletes in the Data Warehouse” from which I will borrow a few terms to differentiate types of data deletions:
- Soft deletes – no physical data deletes are occurring; data records are simply tagged and deactivated.
- Hard deletes with an audit trail – data records are physically deleted, but such deletions are tracked in persistent storage and can offer visibility for previously existing records.
- Hard deletes with no audit trail – the worst-case scenario, data records are deleted and placed in limbo that you don’t have access to.
Working with the first two cases is straightforward, but having the third case at your disposal can evoke a mix of emotions => please refer to the beginning of this post for context. Don't get me wrong; there are valid scenarios where records can be deleted without leaving any traces. Consider a situation involving cached records that aren't fully materialized in your persistent data storage and may require a step to be fully committed in your transactional ledger.
However, when a database record, or a set of records, has been present in your database ledger for several days, survived through multiple evening batch processes, impacted data extracts used for reporting, and all seemed to be ideal in your data world. Until you attempt to reconcile these records in your Enterprise Data Warehouse (EDW) with a sourcing system, and that system provides clear evidence that some of the records have disappeared without a trace, you inevitably begin to ask the fundamental question: Why?
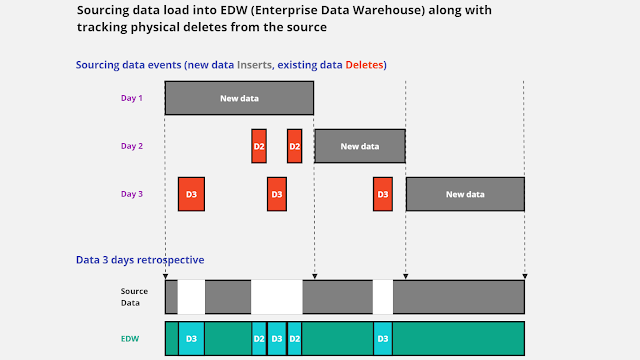
In this figure, Day 1 signifies a successful initial load of sourcing data into your data warehouse. However, on Day 2, a new load arrives, bringing with it the realization that some records no longer exist in the source from Day 1. Day 3 compounds this issue with additional intricate data deletion anomalies.
As a consequence, your sourcing dataset contains not just data gaps, but rather a complete absence of data – the missing sourcing data simply doesn't exist. You now face the challenge of identifying these orphaned records in your data warehouse and making decisions regarding their status, as they no longer provide an accurate representation of valid business data.
One way to address this complex issue is by conducting regular (typically daily) quick checks for any missing records in the source compared to your data warehouse. Then, you can tag those records in your data warehouse as "orphaned" EDW records.
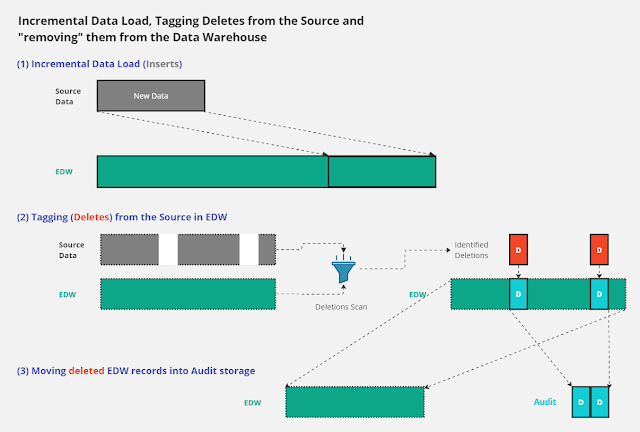
(1) Your usual process for streaming your sourcing data involves incremental data loading. These inserts may include actual new records or updates to previously loaded records.
(2) Following this, you perform a quick comparison of key values between the source and destination. This key can be a single column or a composite key that uniquely identifies records in a table. The need for a speedy comparison arises from the desire to minimize the time spent during data loading. You're primarily interested in identifying and tagging orphaned records in your data warehouse.
(3) While it's possible to keep those tagged or flagged records in the same data warehouse table, doing so initiates continuous efforts to exclude them in your subsequent data processes. This continual exclusion effort poses a challenge because you must identify all previously created objects that may reference the affected table and update them. The risk of missing one of these objects is something you might want to avoid.
An alternative, and possibly better approach is to physically remove these orphaned records from your EDW table. However, do so only after transferring them into a separate audit database storage. This way, when a real audit is conducted, you'll have all the necessary evidence and traces of the data purge.
This audit storage will eventually resemble a place for some of your old family photos and cards written by your loved ones. You may want to revisit them from time to time in an effort to find emotional and analytical closure.


Comments
Post a Comment