(2018-Feb-04) I've had a case working with very large data files as a source for my heat map visualizations in Power BI, where the main file was slightly above 600 MB - http://datanrg.blogspot.com/2018/01/when-its-cold-outside-perhaps-power-bi.html. Not a big deal when you have only a few such data files that you can directly be connected in the Power BI Query Editor. However, it's a whole different story, when you need to maneuver between several hundreds of thousands of such large data files.
A quick side thought though, why don't we try to use the Azure Data Lake for storing such files and then using them for our Power BI data modeling:

Here are some of the highlights of the Azure Data Lake Store:
Built for Hadoop: A Hadoop Distributed File System for the Cloud
Unlimited storage: No fixed limits on file size, account size, or the number of files
Performance Tuned for Big Data: Optimized for massive throughput to query and analyze any amount of data
All Data: Store data in its native format without prior transformation
So here is my story of putting the Azure Data Lake to work with my original data file.
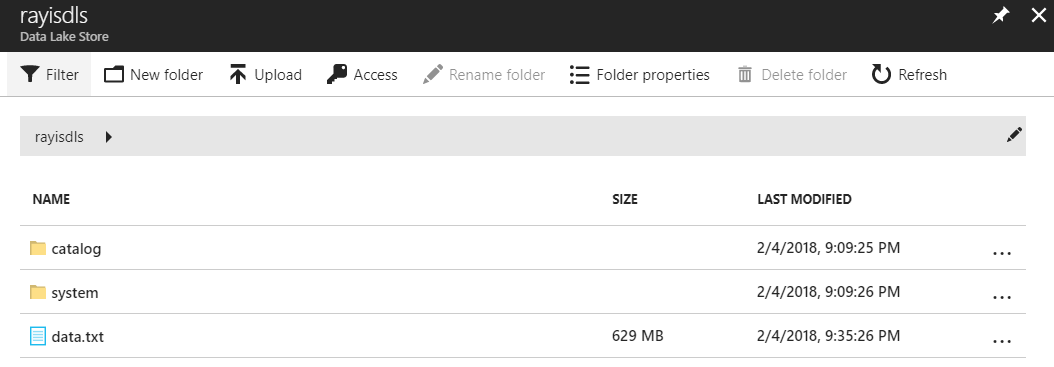
First, I created my instance of the Azure Data Lake store and placed my 629 MB data file in the root folder of its HDFS repository:

Then I went straight to my Power BI desktop environment and connected to my Azure Data Lake Store that I had just created:

For the first time, it will ask for your credential to authentication yourself with your Azure subscription and then it will pass you to explore your data files repository in Azure using the Power BI Query Editor, which is really groovy by itself!


In this testing exercise, I'm only interested in my sourcing data.txt file, and by clicking the Binary link I immerse myself into the very structure of this file, which is basically a formation of 7 columns and ~15 million rows of data.
Here is a quick look at how the initial table extract looks in M language:
It's worthwhile to mention how easy the M language is in converting HDFS data files into a tabular stucture with this Csv.Document function.
And then to transform my Date column value as a year and decimal fraction of the midpoint of the time period being represented, I just copied my previously used M script for this from my previous Power BI report:

Here is the final script that I used in my Azure-based dataset:
then I was able to get to the very same table that I had previously used in my Power BI heat map visualizations.

Basically, I just replaced my originat data table with the very same structure but being sourced from the Azure Data Lake Store, and Power BI data integration experience was only slightly changed at the very beginning.
And while you have your data files in this lake then your data waters won't run dry!
A quick side thought though, why don't we try to use the Azure Data Lake for storing such files and then using them for our Power BI data modeling:

Here are some of the highlights of the Azure Data Lake Store:
Built for Hadoop: A Hadoop Distributed File System for the Cloud
Unlimited storage: No fixed limits on file size, account size, or the number of files
Performance Tuned for Big Data: Optimized for massive throughput to query and analyze any amount of data
All Data: Store data in its native format without prior transformation
So here is my story of putting the Azure Data Lake to work with my original data file.
First, I created my instance of the Azure Data Lake store and placed my 629 MB data file in the root folder of its HDFS repository:
Then I went straight to my Power BI desktop environment and connected to my Azure Data Lake Store that I had just created:

For the first time, it will ask for your credential to authentication yourself with your Azure subscription and then it will pass you to explore your data files repository in Azure using the Power BI Query Editor, which is really groovy by itself!


In this testing exercise, I'm only interested in my sourcing data.txt file, and by clicking the Binary link I immerse myself into the very structure of this file, which is basically a formation of 7 columns and ~15 million rows of data.
Here is a quick look at how the initial table extract looks in M language:
let
Source = DataLake.Contents("https://rayisdls.azuredatalakestore.net"),
#"data txt" = Source{[Name="data.txt"]}[Content],
#"Imported CSV" = Csv.Document(#"data txt",[Delimiter="#(tab)", Columns=7, Encoding=1252, QuoteStyle=QuoteStyle.None]),
#"Changed Type" = Table.TransformColumnTypes(#"Imported CSV",{{"Column1", Int64.Type}, {"Column2", Int64.Type}, {"Column3", type number}, {"Column4", type number}, {"Column5", type number}, {"Column6", Int64.Type}, {"Column7", Int64.Type}}),
#"Renamed Columns" = Table.RenameColumns(#"Changed Type",{{"Column1", "Station ID"}, {"Column2", "Series Number"}, {"Column3", "Date"}, {"Column4", "Temperature"}, {"Column5", "Uncertainty"}, {"Column6", "Observations"}, {"Column7", "Time of Observation"}})
in
#"Renamed Columns"
It's worthwhile to mention how easy the M language is in converting HDFS data files into a tabular stucture with this Csv.Document function.
And then to transform my Date column value as a year and decimal fraction of the midpoint of the time period being represented, I just copied my previously used M script for this from my previous Power BI report:

Here is the final script that I used in my Azure-based dataset:
let
Source = DataLake.Contents("https://rayisdls.azuredatalakestore.net"),
#"data txt" = Source{[Name="data.txt"]}[Content],
#"Imported CSV" = Csv.Document(#"data txt",[Delimiter="#(tab)", Columns=7, Encoding=1252, QuoteStyle=QuoteStyle.None]),
#"Changed Type" = Table.TransformColumnTypes(#"Imported CSV",{{"Column1", Int64.Type}, {"Column2", Int64.Type}, {"Column3", type number}, {"Column4", type number}, {"Column5", type number}, {"Column6", Int64.Type}, {"Column7", Int64.Type}}),
#"Renamed Columns" = Table.RenameColumns(#"Changed Type",{{"Column1", "Station ID"}, {"Column2", "Series Number"}, {"Column3", "Date"}, {"Column4", "Temperature"}, {"Column5", "Uncertainty"}, {"Column6", "Observations"}, {"Column7", "Time of Observation"}}),
#"Removed Columns" = Table.RemoveColumns(#"Renamed Columns",{"Time of Observation", "Observations", "Uncertainty", "Series Number"}),
#"Added Custom" = Table.AddColumn(#"Removed Columns", "Custom", each [Date]),
#"Renamed ColumnsB" = Table.RenameColumns(#"Added Custom",{{"Custom", "Year"}}),
#"Inserted Round Down" = Table.AddColumn(#"Renamed ColumnsB", "Round Down", each Number.RoundDown([Year]), Int64.Type),
#"Added Custom1" = Table.AddColumn(#"Inserted Round Down", "Custom", each ( [Date] - [Round Down] ) * 12 + 0.5),
#"Changed TypeB" = Table.TransformColumnTypes(#"Added Custom1",{{"Custom", Int64.Type}}),
#"Removed Columns1" = Table.RemoveColumns(#"Changed TypeB",{"Year"}),
#"Renamed Columns1" = Table.RenameColumns(#"Removed Columns1",{{"Round Down", "Year"}, {"Custom", "Month"}}),
#"Removed Columns2" = Table.RemoveColumns(#"Renamed Columns1",{"Date"}),
#"Changed Type1" = Table.TransformColumnTypes(#"Removed Columns2",{{"Year", type text}, {"Month", type text}}),
#"Added Custom2" = Table.AddColumn(#"Changed Type1", "Custom", each [Year]&"-"&[Month]&"-01"),
#"Changed Type2" = Table.TransformColumnTypes(#"Added Custom2",{{"Custom", type datetime}}),
#"Renamed Columns2" = Table.RenameColumns(#"Changed Type2",{{"Custom", "Date"}}),
#"Final Change" = Table.TransformColumnTypes(#"Renamed Columns2",{{"Year", Int64.Type}, {"Month", Int64.Type}})
in
#"Final Change"
then I was able to get to the very same table that I had previously used in my Power BI heat map visualizations.

Basically, I just replaced my originat data table with the very same structure but being sourced from the Azure Data Lake Store, and Power BI data integration experience was only slightly changed at the very beginning.
And while you have your data files in this lake then your data waters won't run dry!
• Nice and good article. It is very useful for me to learn and understand easily. Thanks for sharing your valuable information and time. Please keep updating. Power Bi Online Training
ReplyDeleteawesome post presented by you..your writing style is fabulous and keep update with your blogs Big Data Hadoop Online Training India
ReplyDelete