[2017-Aug-08] Support for XML structured files as a data source has been available in Excel, then was introduced into the Power Query data extract engine of the same office application which later migrated into the Power BI data modeling tool.
My recent experience working with XML data files at the last Toronto Open Data user group meeting - https://www.meetup.com/opentoronto/events/240911274/ challenged me to look at XML files at a different angle.
A request was made to analyze Toronto Lobbyist Registry Open Data Set with a very common scenario for an XML data file to hold parent (or master) node elements along with a subset of children (or nested nodes).
Here is an example of this Toronto Lobbyist Registry open XML data file:
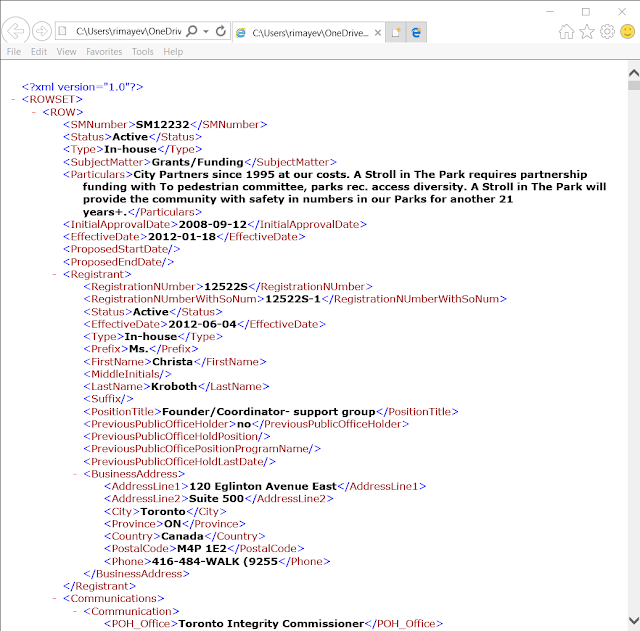
And here is how this file looked in the Power BI Query Editor:

Basically, the ROW parent node had a following list of elements:
- SMNumber
- Status
- Type
- SubjectMatter
- Particulars
- InitialApprovalDate
- EffectiveDate
- ProposedStartDate
- ProposedEndDate
and several sub-nodes which are shown in Power BI query editor as tables:
- Registrant
- Communications
- etc.
My challenge was to build a data model that would enable these main dataset elements analysis along with its subset data elements. It wasn't that intuitive but eventually proved that Power BI is a very decent data modeling environment.
So, first, I made my parent node as a base table with SMNumber as its Primary Key (PK).
Then for each of the sub-node datasets:
1) I had to create a replica of the base table; let's take Communications table for example.
2) Then I removed every column except for the actual column with the Communications table data and I also left the SMNumber, which now had become a Foreign Key (FK) to my base table PK.

3) Then expanded Communications table columns and gave a proper name to a new table within my data model, which now showed all the evidence of a potential One-to-Many relationship between the base and this new table:

After repeating steps 1-2-3 for the other sub-nodes on my XML sourced main table I was able then to create a stable data model to accommodate my future reporting visualizations and data discovery:

One single XML file with parent and children nodes had been transformed into multiple tables, where Power BI took care of empty sub-node elements (please see the null value from the 2nd step of my child node transformation). In addition to that, a referential integrity between tables was in place and I could start working on my visualizations.

I understand that XML data source for Power BI is just a very small member of the family of other supported data sources, and they keep adding new more complicated data resources to stream your data analytics from. However, it's just another proof of how many blades this Power BI Swiss knife can have :)
Happy data adventures!
My recent experience working with XML data files at the last Toronto Open Data user group meeting - https://www.meetup.com/opentoronto/events/240911274/ challenged me to look at XML files at a different angle.
A request was made to analyze Toronto Lobbyist Registry Open Data Set with a very common scenario for an XML data file to hold parent (or master) node elements along with a subset of children (or nested nodes).
Here is an example of this Toronto Lobbyist Registry open XML data file:
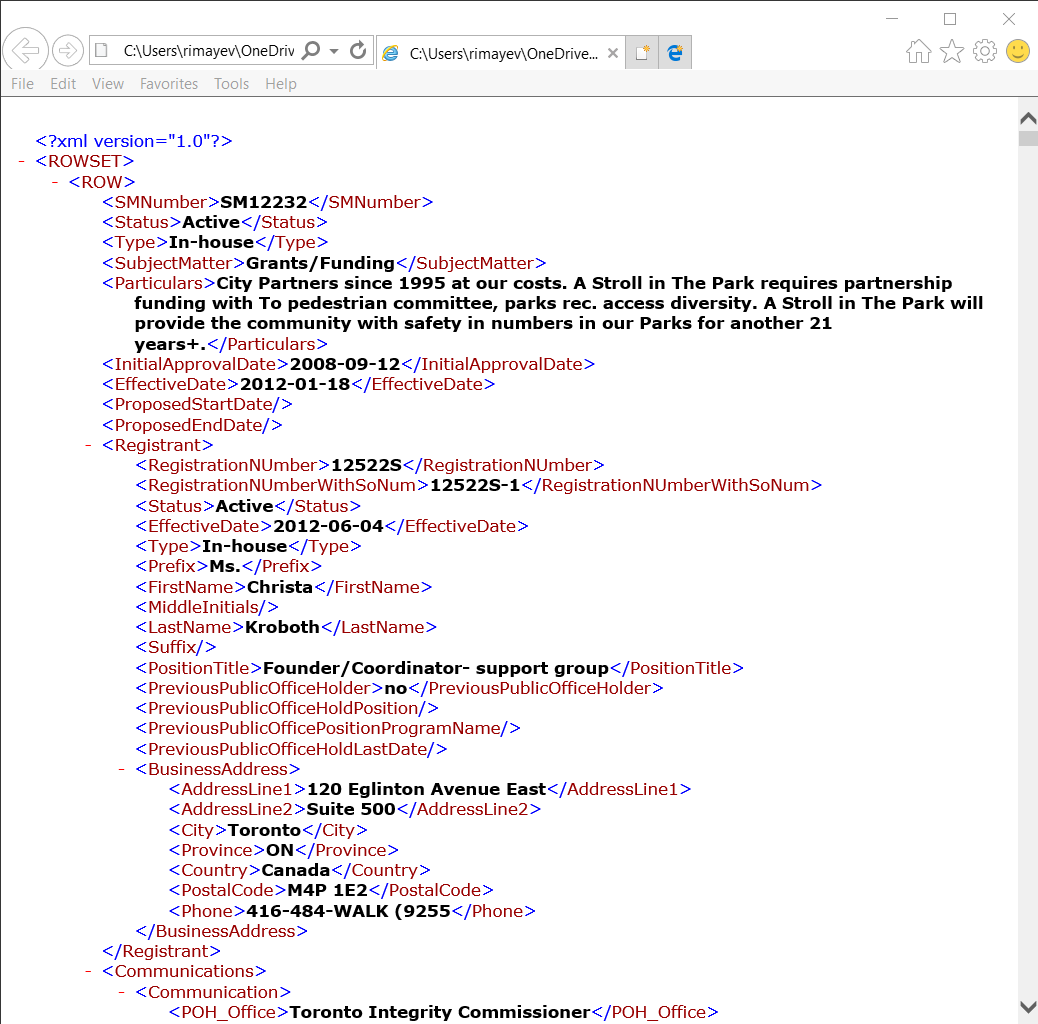
And here is how this file looked in the Power BI Query Editor:

Basically, the ROW parent node had a following list of elements:
- SMNumber
- Status
- Type
- SubjectMatter
- Particulars
- InitialApprovalDate
- EffectiveDate
- ProposedStartDate
- ProposedEndDate
and several sub-nodes which are shown in Power BI query editor as tables:
- Registrant
- Communications
- etc.
My challenge was to build a data model that would enable these main dataset elements analysis along with its subset data elements. It wasn't that intuitive but eventually proved that Power BI is a very decent data modeling environment.
So, first, I made my parent node as a base table with SMNumber as its Primary Key (PK).
Then for each of the sub-node datasets:
1) I had to create a replica of the base table; let's take Communications table for example.
2) Then I removed every column except for the actual column with the Communications table data and I also left the SMNumber, which now had become a Foreign Key (FK) to my base table PK.


After repeating steps 1-2-3 for the other sub-nodes on my XML sourced main table I was able then to create a stable data model to accommodate my future reporting visualizations and data discovery:

One single XML file with parent and children nodes had been transformed into multiple tables, where Power BI took care of empty sub-node elements (please see the null value from the 2nd step of my child node transformation). In addition to that, a referential integrity between tables was in place and I could start working on my visualizations.

I understand that XML data source for Power BI is just a very small member of the family of other supported data sources, and they keep adding new more complicated data resources to stream your data analytics from. However, it's just another proof of how many blades this Power BI Swiss knife can have :)
Happy data adventures!
Hey, this is an example that might help me with understanding XML and Power BI interaction. But I kinda lost you at sub-node data-sets, can you provide me a Power BI file?
ReplyDeleteNice article, users are attracted when they see your post thanks for posting keep updating Power BI Online Training Bangalore
ReplyDeleteMay I know how to create a child table with an XML data string that is part of each record in parent table please.
ReplyDelete